Research
The Jones group focuses on understanding the genomic landscape of cancer using high-throughput sequencing data and machine learning methods. The group is based at Canada's Michael Smith Genome Sciences Centre in Vancouver, Canada and associated with the University of British Columbia. These efforts aim to help the Personalized Oncogenomics (POG) project at BC Cancer and precision cancer medicine in general.
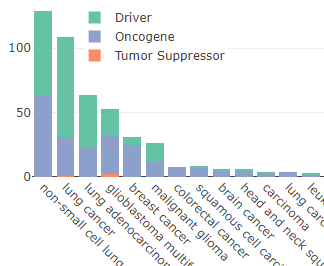
Jake Lever, completed his PhD in the group and focussed on building and using biomedical natural language processing (BioNLP) tools to extract relevant cancer knowledge. He is now a lecturer at the University of Glasgow where he continues to focus on research in this area. These methods are aimed towards the vast PubMed and Pubmed Central Open Access corpora. Below are various projects that we hope will be valuable to the research community.